聚合智慧 | 升华财富
聚合智慧 | 升华财富
产业智库服务平台
产业智库服务平台




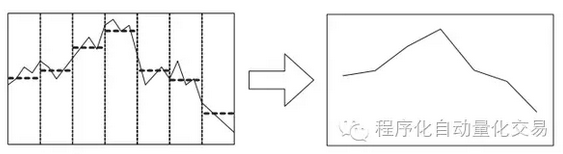
| 高频数据大多“罔不因势象形,各具情态”,其中就包括数据非等间距问题。我们为了克服这些irregularities,我们就要对数据重新表示(re-representation)。 高频价格数据的非等间距问题是首当其冲要解决的。解决的办法一般就是resampling。比如可以自己定义一个时间间隔(segment),重新抽样。这时候的抽样可以直接取用截点的数据(如图1),或者取每个间隔内数据的均值(如图2),根据你的具体情况而定。还有也可以使用线性插值法(linear interpolation)。
图一
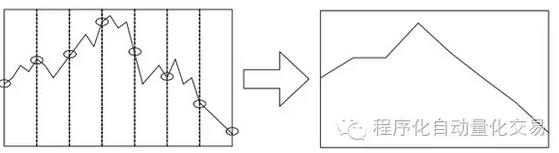
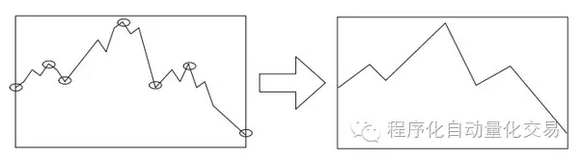
图二 上面提到的方法还仅限于高频时间序列在时域(time domain)中的重新表示,但哪怕我们使用的是等间隔的高频收盘价数据,如果间隔做得比较小,数据的噪声仍然是不可避免的,这就涉及一个频域(frequency domain)的问题。那么对数据做去噪(de-noisying)或者平滑(smoothing)是一个很直接的做法。比如小波去噪(wavelet de-noising)后再做协整检验。或者更学术的做法是使用离散小波变换(DWT)把低频方差和高频方差分解开来,然后把低频和高频的小波系数留下来,将其纳入到协整检验中来,成为一个专用于高频数据协整检验的算法。 其实,高频数据更有利用价值的还是order book。这类数据要是不去研究利用就太可惜了。与价格、成交量之类的time-series不同,order book这类sequence数据并不需要设置抽样点,而是直接把每个时间点上的数据当作一个事件,设定或者拟合一个针对这些事件序列(event sequences)的概率分布。比如著名的Rama Cont[注2]就把order arrival设定为服从泊松分布,每次order arrival都是独立的,order arrival rate则服从指数分布。 当然如果你有简化数据的需要,也可以提取关键数据点,只是这些关键数据点不需要是等间隔的。(如图3)
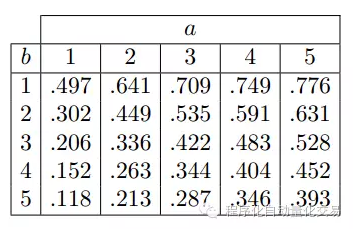
图3 按照上述方法处理好高频数据后,将协整[注1]的配对股票构建一个contingent order,以两者的mid-price之差作为spread,触发交易信号的阈值也可以沿用你习惯的方法来计算。总之,在中低频统计套利中常用的entry-exit strategy都可以作为一个框架拿过来使用,无需赘言。 但任何高频的交易环境下的问题都可以成为这个高频统计套利策略的问题,其中最突出的问题之一就是滑点。我听说有人做过测试,如果每次成交都增加一个tick的滑点,全年的收益就没了。 那么这时候我们可不可以再研究研究order book的变化规律,特别是其中bid/ask的变化规律,摸索出一种计算在mid-price变动之前,配对股票的bid/ask上的orders得到执行的概率,然后根据这些概率判断刚刚触发的交易信号能否得到执行。这样也同时可以规避那些bid-ask价差过大的情况。 我们知道order book的变化就来源于每个价位上的市价单、限价单和撤单指令的flow,每个flow都可以看作一个counting process。有很多实证研究表明,order arrival rate与之到bid/ask的距离有关。Rama Cont[注2]把每个价位上的未成交订单的数量的变化规律看作一个birth-death process,其中每一个event(包括市价单、限价单和撤单指令)都是独立泊松过程: 其中D(·)为death process,xt*θ(p)代表order cancellation rate,µ代表market order arrival rate,B(·)为birth process,λ(p)代表limit order arrival rate,p代表对应的价格。为了建模的简便,我们假设每一个未成交订单被取消的概率都是相等的,也是独立的。 然后就可以用Monte Carlo模拟出在mid-price变动之前,配对股票的bid/ask上的orders得到执行的概率。与此同时,因为这个birth-death process是可以有解析解的,所以Rama Cont用拉普拉斯变换求逆推导出这个概率。推导过程比较复杂,就不写出来了。做个回测,两种方法得到的结果相近(详见[注2])
(数值模拟得到的结果)
(拉普拉斯变换得到的结果) 分别对你的配对股票求取这个概率。当概率高于你预设的阈值时,这次交易可以认定为在mid-price变动之前,bid/ask order可以得到执行,故以限价单分别以bid/ask价位执行建仓。平仓同理。 Rama Cont的模型见仁见智。有的人认为太复杂,也有的人觉得太粗糙。譬如Rama Cont把order arrival看作泊松过程,order duration服从指数分布。但泊松过程太粗糙了,随便拿出一个log化的概率分布根本不成线性的,而且如果对log(duration)做一个自相关系数图,你会发现是拖尾的,也就是个AR过程。另外,等概率的马尔科夫链的假设也很粗糙,与现实的拟合不足,模拟出的概率可信度不足。而且为了追求有解析解而搞这么复杂的数学推导又显得有点没必要,毕竟Monte Carlo模拟在这里也不难实现。 其实沿着Rama Cont的思路,你完全可以将模型简化成一个在技术上没有难度的线性模型,最多加一个时变特征。比如你掌握着order book的当前状态,并且知道下一状态有固定且有限种可能,那么仅取决于哪一种order会先到。所以直接对order arrival rate建模,也就是λ(·),比如像这样一个加入时变特征的线性模型:,分别按照limit/market/cancel、buy/sell、每个quote的价格到当前bid/ask的距离建模。然后计算λ(·)就变成一个工程问题了,无论是怎样做特征工程,还是选择怎样的回归算法。因子可以有arrival rate的滞后项,波动率因子如VIX指数,动量因子如过去若干的tick/second的涨幅,还可以有微观结构因子如bid-ask imbalance,如此等等。回归算法可以先选择线性回归,主要就看Lp regularization的设置了。 最后总结一下吧: 1)拿高频数据做协整,肯定要先做预处理,主要思路就是本文前半部分所说。但这不是难点; 2)难点之一还在于构建统计套利的协整组合,无论是把小波系数纳入协整检验,还是用合适的生成模型或者manifold做个映射什么的,总之要做好你的仿射变换,这就要考察你对策略的理解和设计了; 3)对统计套利这种交易时机敏感型的策略,高频环境下指令的执行就是难点之二。解决这个问题可以有非常多的算法和技术,比如很多人着急他们的机器学习怎么用在交易上,这不就是个好去处嘛。Rama Cont的模型只做个参考就好。但不妨可以把Rama Cont的模型作为一个发凡起例的入门思路,多发掘order book里面新的stylized facts。借助你对市场的观察,开发你的交易执行模块,才是最好的。 注1:我这里所指的“协整”,不一定是时间序列教材里看到的若干种协整检验。在统计套利的语境下,协整有着更严格的内含和更丰富的外延。总之,你可以根据你对模型和数据的探索,做出某种仿射变换,构建你的协整组合。 注2:来自于 Cont, Stoikov and Talreja, A stochastic model for order book dynamics 责任编辑:张文慧 |
【免责声明】本文仅代表作者本人观点,与本网站无关。本网站对文中陈述、观点判断保持中立,不对所包含内容的准确性、可靠性或完整性提供任何明示或暗示的保证。请读者仅作参考,并请自行承担全部责任。

本网站凡是注明“来源:七禾网”的文章均为七禾网 www.7hcn.com版权所有,相关网站或媒体若要转载须经七禾网同意0571-88212938,并注明出处。若本网站相关内容涉及到其他媒体或公司的版权,请联系0571-88212938,我们将及时调整或删除。
首页广告.png)




七禾研究中心负责人:刘健伟/翁建平
电话:0571-88212938
Email:57124514@qq.com
七禾科技中心负责人:李贺/相升澳
电话:15068166275
Email:1573338006@qq.com
七禾产业中心负责人:果圆/王婷
电话:18258198313
七禾研究员:唐正璐/李烨
电话:0571-88212938
Email:7hcn@163.com
七禾财富管理中心
电话:13732204374(微信同号)
电话:18657157586(微信同号)
 七禾网 |  沈良宏观 |  七禾调研 |  价值投资君 |  七禾网APP安卓&鸿蒙 |  七禾网APP苹果 |  七禾网投顾平台 |  傅海棠自媒体 |  沈良自媒体 |
© 七禾网 浙ICP备09012462号-1 浙公网安备 33010802010119号 增值电信业务经营许可证[浙B2-20110481] 广播电视节目制作经营许可证[浙字第05637号]